




We run a studio. We have retainer clients. Those retainer clients have backlogs. And if I'm being honest, a lot of what sits in those backlogs isn't hard. It's just time-consuming.
"Change this button color." "Update the hero copy." "Fix the padding on mobile." "Add a new team member to the about page." These are real tickets from real clients, and every single one requires a context switch. Pull up the repo. Read the ticket. Find the file. Make the change. Open the PR. Wait for CI. Merge. Deploy. For a change that took 10 seconds of actual thinking, the process took 20 minutes of faff.
That's the throughput tax of agency life. Not the complex architectural work. Not the system redesigns or the tricky state management bugs. Those are the tickets we're here for. The small stuff is what buries the team.
So we built Satoru as part of our agentic workflows practice. It's a background agent that picks up low-complexity tickets from client Linear boards and ships PRs without a human touching the keyboard. It runs in a box. Here's why we built it, what I learned from companies doing this at much larger scale, and why I think the agency might change rapidly.
Also clients, if you're reading this, R&D isn't free, hire us for consultancy. Nobody else is going to throw a background agent in as a sweetener...
The retainer problem nobody talks about
Every agency I know runs into the same pattern. You sign a retainer client. The first few months are great. Big builds, meaty features, architectural decisions that need your full attention. Then maintenance mode kicks in.
The backlog fills up with small stuff. Not unimportant stuff. The client needs these things done. But they're not the kind of work that justifies pulling a senior engineer off a complex build. So they sit. They accumulate. The client gets frustrated. You get frustrated. The backlog becomes a source of tension in every standup and every monthly review.
We tried the obvious solutions. Junior devs dedicated to small tickets. Batching amends into dedicated sprint days. Multi-agent orchestration. They all have the same problem: a human still has to context-switch into each project, understand the codebase, make a small change, and context-switch out. The overhead is constant regardless of the ticket size.
What we actually needed was something that could run in the background, pick up a well-specified ticket, make the change in a sandbox, and open a PR for review. No babysitting. No pairing. Just: here's the ticket, here's the codebase, go.
Why off-the-shelf wasn't enough
There's a framework from Chris Weichel at Ona that nails this. He calls it "time between disengagements", how long an AI coding tool can operate before it needs human input.
Think of it as autonomy levels:
- Seconds: Tab completion, GitHub Copilot. You're steering constantly.
- Minutes: Cursor, Claude Code. Multi-step execution, but you're in the loop giving feedback every few minutes.
- Hours: Background agents. You hand off a task, go do something else, come back to a finished PR.
- Days: Doesn't exist yet. "...but what about Ralph loops" shut up
We were stuck in the minutes tier. Cursor and Open Code are great tools, and we use them daily for the complex work where you want to be in the loop. But "being in the loop" means someone is sitting at a keyboard. That someone has a finite number of hours, and those hours should go toward the work where human judgment matters, things like building the architectural foundation that agents and AI tools need to work effectively.
For a ticket that says "change the accent color from blue-600 to indigo-500 across the marketing pages," you don't need a human in the loop. You need a human to review the result. Big difference.
The off-the-shelf tools don't solve this because they're designed for interactive use. They assume a developer is present. We needed the opposite: something that runs while the developer is doing something else entirely.
What the industry is building
I'll be honest, a bit more than a week before we started building Satoru I was publicly skeptical about all of this. The background agent spiel felt like marketing. Everyone announcing their agent, nobody showing real world examples of both the good and bad. Even less so, most folks left out the blueprint to build one.

Well guess what? I was partially wrong. I now believe the data from the companies below is within the realm of realism. But I still think the risk of turning these into slop cannons is underrated. Shipping volume means nothing if the code is garbage. More on that in the lessons section.
Stripe's Minions: 1,000+ PRs per week
Stripe's internal agent system, called Minions, now merges over 1,000 PRs per week. One-shot, end-to-end coding agents. The human writes the spec, the agent writes the code, the human reviews the PR. That's it.
Published by Alistair Gray on Stripe's internal tooling team. The numbers are wild. They're not using agents for side projects or internal tooling experiments. This is production code getting merged at scale, across Stripe's main codebase.
The model is simple: agents write, humans review. The review step isn't going anywhere. But the writing? That's increasingly automated for well-defined tasks.
Ramp's Inspect: 30% of all PRs
Ramp is actually the company that mostly inspired us to build Satoru. We love seeing some of the crazy AI stuff they've built, and frankly, anybody that makes taxes and expenses simpler is a friend of ours.
Ramp built an agent called Inspect that, within months of deployment, was producing roughly 30% of all pull requests to their frontend and backend repositories. Thirty percent.
Their architecture is worth studying. They run sandboxed VMs on Modal, each with a full dev environment: Vite, Postgres, Temporal, the works. Pre-built images get refreshed every 30 minutes so agents start with a warm cache. They use OpenCode as the underlying coding agent.
Developers can kick off agent tasks from Slack, a web interface, or a Chrome extension. It's multi-surface by design, because if the agent only lives in your IDE, you're back to the "someone has to be sitting there" problem.
The line that stuck with me from their writeup: "Owning the tooling lets you build something significantly more powerful than off-the-shelf." That's been our experience exactly.
Cursor's long-running and self-driving agents
Cursor has published two pieces of research that, taken together, paint a picture of where this is headed. Their long-running agents can execute for 36+ hours, producing much larger PRs with merge rates comparable to shorter runs. Theo Browne shipped two architecture overhauls running five agents in parallel. Zack Jackson compressed a quarter's worth of planned work into days: a 52-hour run, 151,000 lines touched.
Their self-driving codebase experiment pushed further with a multi-agent hierarchy. A root planner breaks down the task, recursive subplanners decompose further, and workers execute in isolated repo copies. At peak throughput: roughly 1,000 commits per hour, 10 million tool calls over one week. The system accepts some error rate in exchange for throughput, with a final "green branch" fixup pass that resolves conflicts and broken tests.
The problem is, I'm skeptical as to how well this could be implemented in a real world project, but I'd like to believe this isn't just smoke and mirrors.
Our architecture: Linear-native, multi-tenanted, agency-first
Here's where our story diverges from Stripe and Ramp. They're product companies building agents for their own codebases. We're an agency building agents that work across dozens of client codebases simultaneously.
That changes everything about the architecture.
The multi-tenant Linear application
So we kind of cheated by saying we built the vast majority of this in a week. The truth is we built a multi-tenanted Linear application that gives each retainer client their own board a while back. That is pretty important for our model. Actually, it's basically the coal for the steam engine.
Clients add tickets directly. Then our team assesses complexity. If a ticket is straightforward (well-specified, low risk, doesn't touch shared infrastructure), Satoru can pick it up.
No time billed. No human context-switch. The client gets faster turnaround on the small stuff. We get to spend our hours on the work where agency expertise actually matters.
The flow looks like this:
- Client adds ticket to their Linear board
- We triage and tag complexity
- Low-complexity tickets get assigned to Satoru
- Satoru clones the repo, spins up a sandbox, makes the change
- Satoru opens a PR with the ticket linked
- Engineer reviews, approves, merges
- Deployment happens through the existing CI/CD pipeline (Just use Vercel)
Here's what that looks like in practice. A ticket gets assigned to Satoru in Linear, it picks it up, and about 20 minutes later there's a PR ready for review.
Satoru's first ticket
The engineer reviews every PR. That's non-negotiable. But reviewing a clean PR takes five minutes. Writing it from scratch, with all the ceremony, takes thirty.
Why "personalised software" matters here
If you haven't heard this term floating around, you're obviously not soullessly scrolling X all day, good job. "Personalised software" is not a generic project management tool with AI bolted on. It's a purpose-built system designed around exactly how our studio operates.
We control the full loop: ticket intake, triage, sandbox execution, PR, review, deploy. Every step is built for our workflow because we built it. The agent slots into the pipeline naturally because the pipeline was designed with the agent in mind from the start.
Every general-purpose tool we evaluated assumed a single team working on a single codebase. Agency life doesn't work that way. We'd rather build the tool that fits our workflow than cram our workflow into someone else's assumptions about how software gets made.
Context is the hard part
Getting an agent to write code is, honestly, the easy part. The hard part is giving it enough context to write the right code.
A ticket that says "change the button color to indigo-500" is useless without knowing: Which button? Which component file? Is the color defined as a CSS variable, a Tailwind class, or hardcoded? Does the project use a design token system? Are there dark mode variants?
The Linear integration solves part of this. Tickets carry project context: which repo, which framework, which conventions. Satoru gets a brief that includes the project's architecture notes, component structure, and any relevant style guidelines. This is the same principle behind our Claude skills: encode the conventions once, and every AI interaction benefits from that context.
But the thing that actually makes it work is the sandbox. Satoru doesn't guess about the codebase. It clones it, runs the dev server, and can actually verify that its changes work before opening the PR. A sandboxed environment with a running dev server catches the obvious mistakes that would otherwise waste a reviewer's time.
Linear is clearly building with AI context at the forefront.
Linear → Your AI coding tool. Open any issue directly in Claude Code, Codex, Conductor, Cursor, GitHub Copilot, OpenCode, Replit, v0, or Zed – preloaded with full context and a custom prompt.
Under the hood: Open-Inspect
That's the workflow layer (how tickets flow from client boards to merged PRs). Here's what powers it. We call the platform Open-Inspect. Satoru runs inside it.
Architecture overview
Three tiers connected by WebSockets: a web client, a control plane, and sandboxed compute. Bot integrations let you kick off sessions from Slack, GitHub, or Linear.
Web client
Stack: Next.js 16, React 19, deployed to Vercel or Cloudflare Workers (via OpenNext)
GitHub OAuth handles authentication. The dashboard lets you list, create, and monitor coding sessions. A persistent WebSocket connection to the control plane streams Satoru's output in real time as it works through a task. No polling, no refreshing.
Control plane
Stack: Cloudflare Workers, Durable Objects, D1 (SQLite)
This is the brain. Every coding session is its own Durable Object with dedicated SQLite storage.
- Session lifecycle: create, run, pause, resume, stop
- WebSocket hub: bridges the web client and the sandbox bidirectionally
- D1 database: session index, repo metadata, encrypted repo secrets
- GitHub App integration: repo access tokens, cloning, PR creation
- Auth and permissions: controls who can do what
Durable Objects are the right primitive here. Each session needs isolated state, its own WebSocket connections, and the ability to hibernate when idle. D1 gives you a lightweight relational store without managing infrastructure.
Data plane
Stack: Modal (Python), FastAPI
This is where Satoru actually runs. Modal spins up isolated sandbox environments on demand.
- Sandbox creation: each session gets its own containerized dev environment with the repo cloned, dependencies installed, and a dev server running
- Warm pool: pre-warmed sandboxes so there's no cold boot penalty
- Snapshots: save and restore session state for persistence across runs
- WebSocket bridge: streams agent events back to the control plane in real time
Satoru has access to the full repo inside the sandbox. It can run tests, start dev servers, and verify its own changes before opening a PR. The container boundary is the security model. Nothing inside the sandbox can reach anything outside it.
Bot integrations
All built as Cloudflare Workers with Hono.
Slack Bot: listens for messages, classifies intent, and routes to the right repo to kick off a session. Engineers can trigger Satoru from a Slack channel without opening the dashboard.
GitHub Bot: handles PR review assignments and responds to @mention commands. You can ask Satoru to pick up work directly from a PR comment.
This isn't just rubber-stamping either. During a spam protection implementation, Satoru flagged a honeypot security regression that would have gone to production: the refactored code returned a 422 error on honeypot fields instead of a silent 200, which tells bots they've been caught and defeats the entire purpose. It also caught that BotID client initialization only loaded in production while the server-side check ran unconditionally, meaning local dev would hang or fail. Both were the kind of subtle integration bugs that slip past a quick human review.
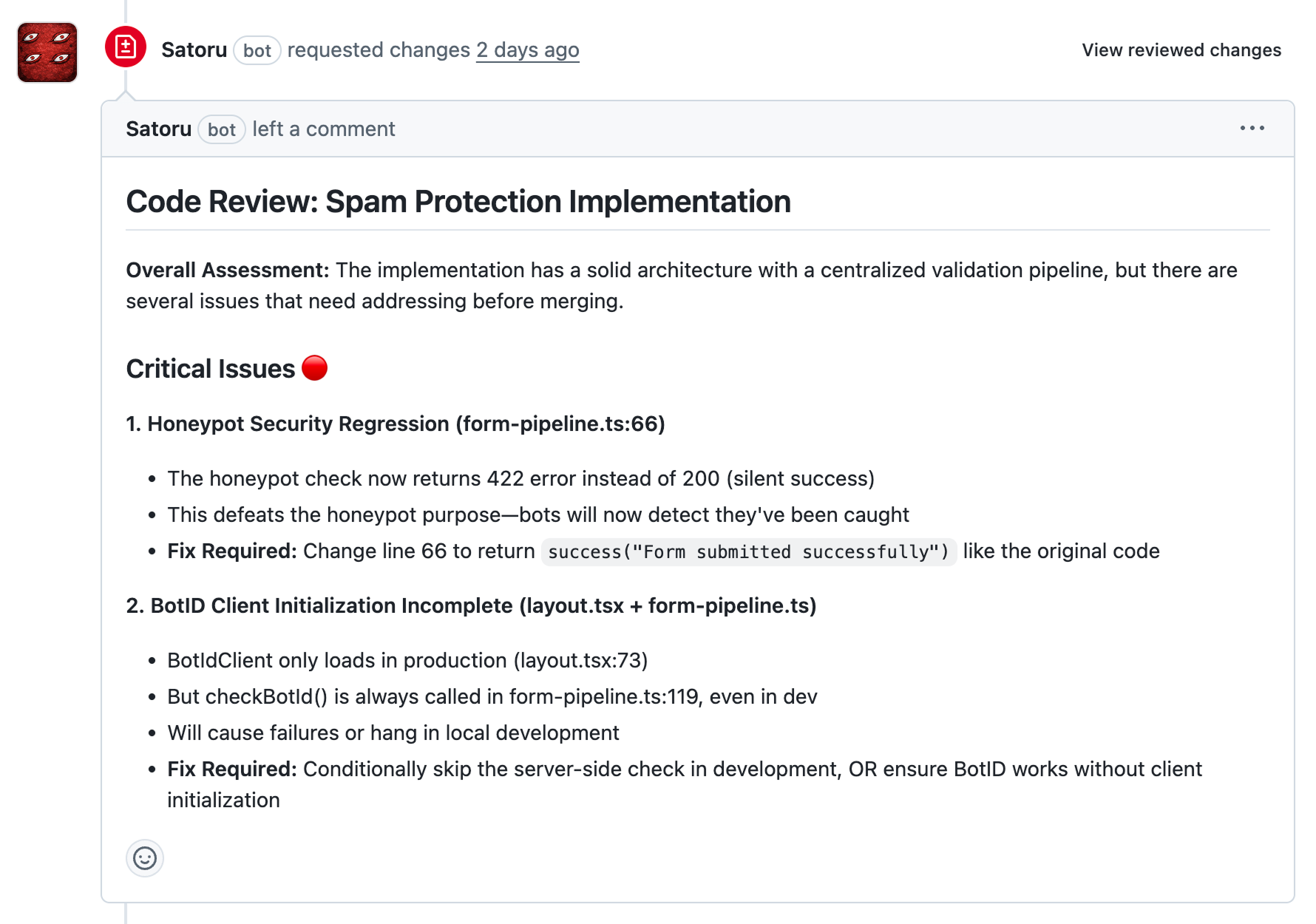
The agent catches what tired eyes miss. That's the point.
Linear Bot: receives Linear agent webhooks and creates coding sessions from issues. This is how the triage flow connects to the execution layer. Tag a ticket for the agent in Linear and it flows through to a running sandbox automatically.
Shared foundation
@open-inspect/shared: a TypeScript package that every other component imports. Shared types, auth utilities, and model definitions. It builds first. Everything else depends on it.
Infrastructure
Terraform provisions everything: Workers, Durable Objects, D1 databases, secrets, Modal deployments. One config to rule them all. No clicking around in dashboards.
D1 migrations handle schema versioning. Applied automatically in integration tests and on deploy.
CI/CD runs on GitHub Actions. Push to main auto-deploys changed services. Terraform handles the control plane and D1 migrations. Modal deploys the data plane. Every PR gets lint, typecheck, and tests.
| Component | Tech | Role |
|---|---|---|
| Web Client | Next.js 16 + React 19 | Dashboard, OAuth, real-time UI |
| Control Plane | CF Workers + Durable Objects + D1 | Session management, WebSocket hub |
| Data Plane | Modal + Python + FastAPI | Sandboxed coding environments |
| Slack Bot | CF Workers + Hono | Slack-triggered sessions |
| GitHub Bot | CF Workers + Hono | PR review and @mention commands |
| Linear Bot | CF Workers + Hono | Linear webhook-triggered sessions |
| Shared | TypeScript | Types, auth, models |
| Infra | Terraform + GitHub Actions | Provisioning and CI/CD |
Early lessons
We shipped Satoru's first PR about a week ago. It's early. We're testing it against our own internal codebases before pointing it at client work, and every PR still gets a senior engineer's eyes on it before merge.
But even at this stage, a few things have already become obvious.
Don't ship slop
Cursor's self-driving codebase experiment peaked at 1,000 commits per hour. They got there by accepting breakage and running a fixup pass at the end. That works when you own the whole codebase and can afford to clean up after yourself and have passionate developers submitting issues like they're going out of fashion.
We can't afford to do that. These are client codebases. A sloppy PR that gets merged because a reviewer was in a hurry is a bug report next week and a trust problem next month. So Satoru doesn't get to be "close enough." Every PR goes through the same review bar as human-written code. If the agent misses an import or gets a style convention wrong, it doesn't ship. It gets sent back.
The review step is the bottleneck, not the writing
Ona's essay on industrialising software development makes a point about factory floors: optimising one station doesn't help if the bottleneck is somewhere else.
For background agents, the pipeline is: ticket, code, test, review, integrate, deploy. The agent speeds up the code-writing station. But if reviews take two days or the deployment pipeline takes 45 minutes, faster writing barely matters.
We've spent as much time on making PRs easy to review (clear descriptions, linked tickets, before/after context) as we have on making the agent write better code. That's where the actual time savings show up.
Build your own, but only if you have to
If off-the-shelf tools cover your workflow, use them. Building agent infrastructure is real work and ongoing maintenance.
Our workflow is specific enough that we had no choice. We need:
- Multi-tenanted client access across dozens of repos
- Per-project conventions and architecture notes fed to the agent
- Triage-based routing between humans and agents
- Client-facing visibility into agent-generated work
- Billing integration (agent tickets aren't billed as engineer hours)
None of that exists in Cursor or Claude Code. We built it because our business model requires it, not because building it was fun. (It was fun. But that's beside the point.)
Where this goes for agencies
Satoru is on training wheels. We're running it against internal projects, building confidence in the output, and learning where it falls over. The plan is to roll it out to client codebases once we trust the review loop enough. That trust gets built one PR at a time.
Ramp hit 30% of all PRs within months. I don't know if we'll hit the same number, but we don't need to. Even 10% of ticket volume handled by the agent frees up meaningful engineering time for the work clients actually hired us to do: system architecture, performance audits, migration planning. Not "change this button color."
The agency model has always had a tension between "we're experts you hire for hard problems" and "we also need to update your blog page title." Background agents dissolve that tension. Hard problems get the humans. Blog page titles get the agent.
I'm watching what this means for retainer pricing too. If a chunk of ticket volume isn't billed as engineer time, clients get more value per dollar spent. That shifts the conversation from "how many hours do we get" to "how many outcomes do we get." I'd rather sell outcomes anyway, leave timekeeping for Casio.
If you're an agency or engineering team thinking about building your own background agent setup, we're happy to talk shop. We've made plenty of mistakes already. Might as well save you a few.